BigQueryのテーブルを作成する際に最初に検討すること
はじめに
BigQueryとはいえデータ量が多いと時間はかかるので、速度がある程度求められるものに関してはパフォーマンスチューニングの検討をした方が良さそう
BigQuery を最大限に活用するための重要なベスト プラクティスの 1 つが、テーブルのパーティショニングとクラスタリングです 公式ブログから引用:https://cloud.google.com/blog/ja/products/data-analytics/skip-the-maintenance-speed-up-queries-with-bigquerys-clustering
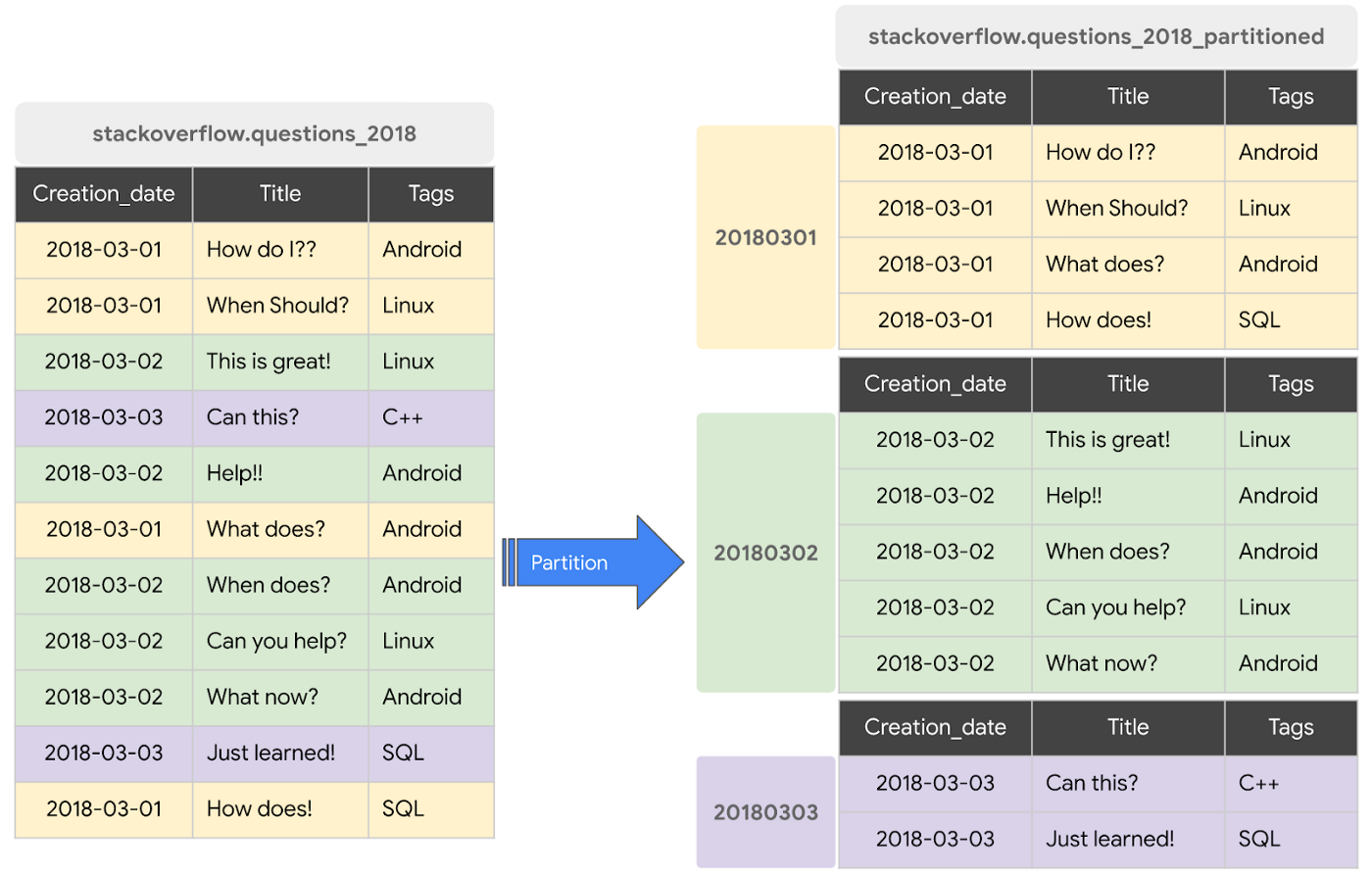
パーティショニング
- データの取り込み時間、TIMESTAMP/DATE 列、INTEGER 列を使用して、大きなテーブルを多数の小さなパーティションに分割可能
- フィルタを表現するクエリを使用することでスキャンするデータの全体量を減らし、クエリパフォーマンスの向上と費用削減が可能
- パーティション前のデータとパーティション後のパフォーマンス比較
作成手順
bq mk --table \ --schema SCHEMA \ --time_partitioning_field COLUMN \ --time_partitioning_type UNIT_TIME \ --time_partitioning_expiration EXPIRATION_TIME \ --require_partition_filter=BOOLEAN \ --project_id PROJECT_ID \ DATASET.TABLE
分割テーブルの注意点
- 文字列型をパーティションキーに割り当てることはできない
- 4000種類以上あるデータをパーティションに割り当ててはいけない
- 日付を指定しれいれば、約11年分は保存可能(365 * 11 = 4015)。11年を超える場合はパーティションに有効期限を設けて古いデータから消していくとかの対応すればいける
- パーティションの変更数が1日に30,000回を超えてはいけない
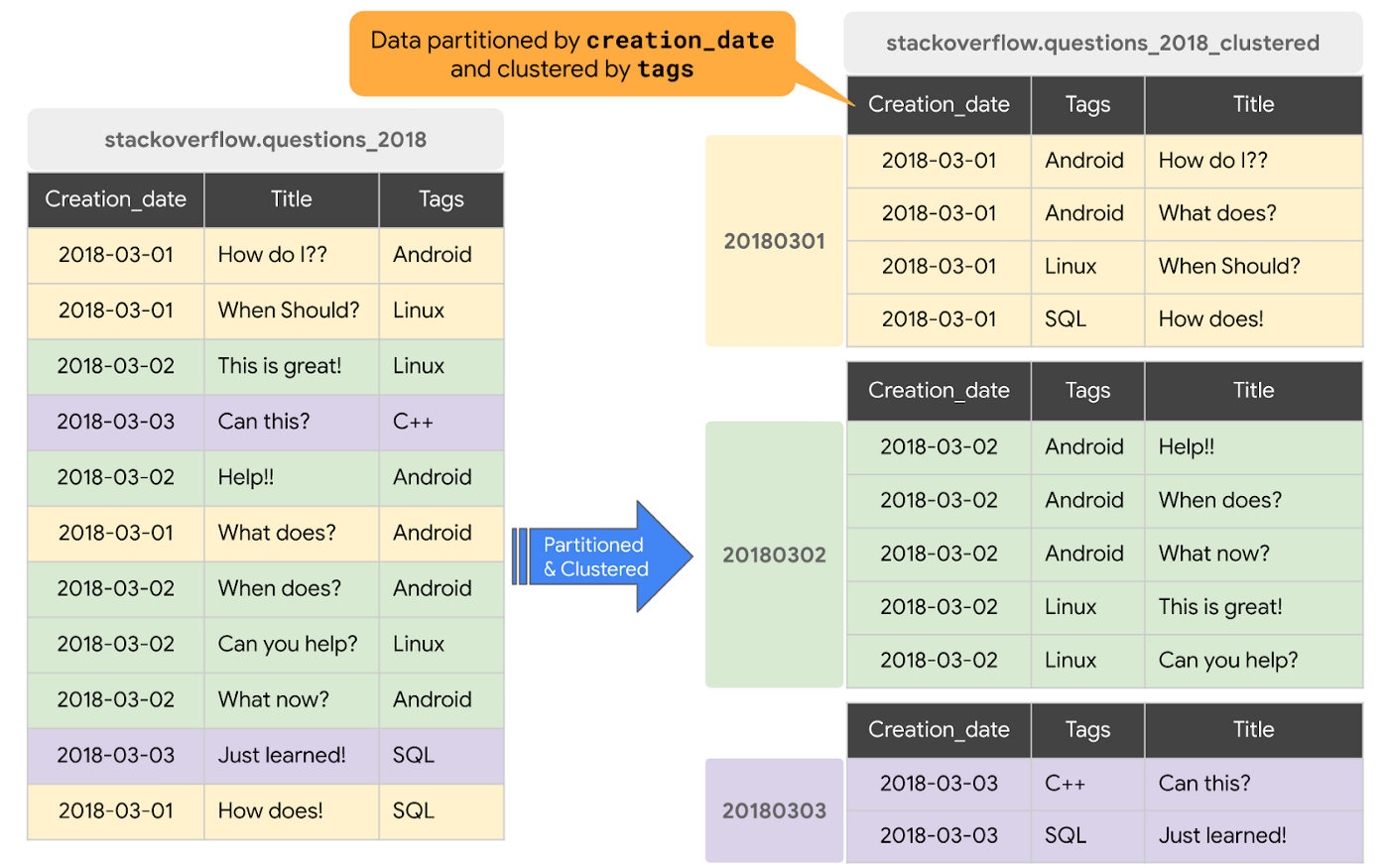
クラスタリング
- クラスタ化されると、テーブルのスキーマ内の1つ以上の列のコンテンツに基づいて、BigQueryがバックグラウンドで自動再クラスタリングを実行(ソートした状態で配置)
- クラスタリングには通常、カーディナリティの高い非時間列が推奨
- MySQLでいうインデックスのようなイメージ
- クラスタリング前のデータとクラスタリング後のパフォーマンス比較
複数カラムの指定
いわゆるインデックスのようなものなので、複数カラムで作成する場合にはMySQLの複合インデックスをイメージするとわかりやすい。同様に順序が重要で右の順序(age, last_name, first_name)で作成する場合は以下の図のようになる。
 【図解】B-treeを理解し、複合インデックスの順番を正しく作るから引用
【図解】B-treeを理解し、複合インデックスの順番を正しく作るから引用
順序に関してはWHEREの頻度が高い順からインデックスをつけると良い。上記の例では、年齢から何かを調査することが多いテーブルだろう。逆にlast_nameがインデックスの先頭に来ていたら、連絡先のような名前で検索かけることが多いテーブルということがわかる。
作成手順
bq mk \ --table \ --expiration INTEGER1 \ --schema SCHEMA \ --clustering_fields CLUSTER_COLUMNS \ --description "DESCRIPTION" \ --label KEY:VALUE,KEY:VALUE \ --project_id PROJECT_ID \ DATASET.TABLE
パーティショニングとクラスタリングの使い分け
パーティションの利用
- 日付/時間列があり、日付/時間でフィルタするクエリがある
- パーティションの有効期限設定を使いたい
- dry-run でスキャン量 (費用) 見積もりを厳密に行いたい
クラスタリングをの利用